Digitale Linguistik | Korpuslinguistik | Diskurslinguistik
Als Professorin für Methoden der Sprachdatenanalyse an der Zürcher Hochschule für Angewandte Wissenschaften (ZHAW) interessiere ich mich für die Art und Weise, wie sprachliche Muster in grossen Sprachdatensammlungen identifiziert, analysiert und für die Verbesserung der kommunikativen Praxis genutzt werden können. Mein Forschungsschwerpunkt liegt in der Entwicklung von digitalen, datengetriebenen Methoden für die Analyse gesellschaftlich relevanter Diskurse. Dabei verbinde ich korpuslinguistische Ansätze mit Verfahren des Machine Learnings und der Künstlichen Intelligenz.

Kontakt:
julia.krasselt@zhaw.ch
Theaterstrasse 17
8401 Winterthur
CV
- seit Juni 2024: Professorin für Methods of Language Data Analysis, ZHAW Institute of Language Competence
- seit 2021: Projektleitung Digitales Textkorpus Swiss-AL (ZHAW)
- seit 2017: Wissenschaftliche Mitarbeiterin an der Zürcher Hochschule für Angewandte Wissenschaften, Departement Angewandte Linguistik (Winterthur, Schweiz)
- 2016: Dr. phil. in Linguistik, Ruhr-Universität Bochum, Deutschland (Betreuung: Stefanie Dipper)
- 2011–2015: Wissenschaftliche Mitarbeiterin an der Ruhr-Universität Bochum, Deutschland (DFG-gefördertes Projekt „St. Anselmi Fragen an Maria. Digitale Erschließung, Auswertung und Edition der gesamten deutschsprachigen Überlieferung (14.–16. Jh.)“)
- 2010: Magistra Artium in Germanistik, Psychologie und Geschichte, Universität Leipzig, Deutschland
Forschung
Forschungsschwerpunkte: Digitale Linguistik, Korpuslinguistik, Diskurslinguistik, datengetriebene linguistische Methoden, Künstliche Intelligenz, Computerlinguistik, gebrauchsbasierte Grammatik
Laufende Forschungsprojekte
- Geschichte der „Öko-Architektur“ in der Schweiz, 196X–199X. Eine architekturhistorische, korpuslinguistische und gendertheoretische Analyse (gefördert durch den SNF)
- Monitoring Vaccination Discourses (gefördert durch den SNF)
- Feldstudie: Digitale Diskursanalyse in der Schweiz (gefördert durch SAGW)
- New Digital Tools for Media Monitoring and Discourse Analysis (Digitalisierungsinitiative Zürich)
Abgeschlossene Forschungsprojekte
- Stärkung von ORD-Kompetenzen in den Angewandten Wissenschaften: Open Educational Resources für Swiss-AL
- Swiss-AL: Linguistic ORD Practices for Applied Sciences
- Monitoring Sustainability
- Plattform für Energieforschung
- Berichte schreiben im Massnahmenvollzug
- Public COVID 19 pandemic discourses – a focus on vector populations (COVIDisc) (SNF)
- Digitale Transfer-Plattform für COVID-19-Forschungen
- Korpusgestütztes Diskurs-Tracking zur Strategie Antibiotika-Resistenz (Bundesamt für Gesundheit)
- Automatisiertes Fahren im öffentlichen Diskurs: Botschaft und Wirkung
- A corpus linguistic approach to childhood public health (SSPH+)
- „Swiss-AL Textkorpora: Besondere Herausforderungen und Möglichkeiten linguistischer Daten unter Open-Data-Perspektive“
- Energiediskurse in der Schweiz (Bundesamt für Energie)
- Gefühlte Realitäten – konstruierte Wirklichkeiten. Entwicklung eines dynamischen Modells zur Analyse, Beschreibung und Beobachtung von öffentlichen Diskursen mit Public Impact (Gebert Rüf)
- RaPEnDI – Radar Public Energy Discourse (ZHAW)
- Situative korpusgestützte Diskursanalyse zur Strategie Antibiotikaresistenzen in der Schweiz (Bundesamt für Gesundheit)
Ausserdem forsche ich im Bereich der Historischen Linguistik:
- Dissertation: Der Verbalkomplex im Frühneuhochdeutschen. Eine korpuslinguistische Untersuchung zur Serialisierung zwei- und dreigliedriger Verbalkomplexe. [PDF]
- DFG-gefördertes Projekt „St. Anselmi Fragen an Maria. Digitale Erschließung, Auswertung und Edition der gesamten deutschsprachigen Überlieferung (14.–16. Jh.“ (abgeschlossen)
Publikationen
2026
Krasselt, J., Dreesen, P., Stücheli-Herlach, P., Lemmenmeier-Batinić, D., Geckeler, S., Rothenhäusler, K. & Fluor, M. (2026). Swiss-AL: Plattform für Sprachdaten in den Angewandten Wissenschaften. Zeitschrift für germanistische Linguistik, 54(1), S. 210-229. https://doi.org/10.1515/zgl-2026-2008
2025
Krasselt., J. (2025). What can a Multidimensional Language Model Tell Us about Architecture? In Gerber, A., Atalay Franck, O., & Mieskes, M. (Hrsg.), Architectural Intelligence in the Age of Artificial Intelligence. Transkript, S. 113-123. https://doi.org/10.1515/9783839430699
Bubenhofer, N., Krasselt, J., Prinz, M., Kato, H. (2025). Studienbuch Linguistik. Band 1: Gegenwartssprache. De Gruyter. [https://doi.org/10.1515/9783111516172]
Krasselt, J. Data Analysis with Swiss-AL for textual data. CLARIN-CH Training Session. 12. Mai 2025.
Krasselt, J. Reusing Data for Teaching and Secondary Analysis. CLARIN-CH Training Session. 02. Juni 2025.
Dreesen, P., Fluor, M., Geckeler, S., Krasselt, J., Lemmenmeier-Batinić, D., Rothenhäusler, K., & Suremann, Isabelle. Finding out what it’s truly about. Creative combination of AI-assisted discourse and corpus linguistics. VALS-ASLA Studientag 2025. Winterthur, 06. Juni 2025
2024
Schwägerl, Ch., Stücheli-Herlach, P., Dreesen, P., & Krasselt, J. (2024). Dealing with risk in stakeholder dialogue: identification of risk indicators in a public service media organization’s conversation and discourse with citizens. Journal of Communication Management, 28(2), S. 247–271. https://doi.org/10.1108/JCOM-01-2023-0002
Krasselt, J., & Dreesen, P. (2024). Topic Models indicate textual aboutness and pragmatics: Valuation practices in Islamophobic discourse. Journal of Cultural Analytics. https://doi.org/10.22148/001c.92535
ZHAW School of Applied Linguistics (Hrsg.). (2024). Angewandte Linguistik für Sprachberufe. De Gruyter. (Kapitel „Korpusanalyse“) https://doi.org/10.1515/9783110786767
2023
Krasselt, J., Dreesen, P., Stücheli-Herlach, P., Lemmenmeier, D., Cho, S., Rothenhäusler, K., & Fluor, M. (2023). Swiss-AL: Platform for Language Data in Applied Sciences: On Challenges in the Field of Language Open Research Data. Proceedings of the 1st Conference on Research Data Infrastructure (CoRDI) – Connecting Communities. https://doi.org/10.52825/cordi.v1i.249
Dreesen, P., & Krasselt, J. (2023). Swiss-AL: Plattform für Sprachdaten zur Analyse öffentlicher Kommunikation in der Schweiz. Publizistik, 86, S. 291–303. https://doi.org/10.1007/s11616-023-00785-9
Krasselt, J., Dreesen, P., Fluor, M., & Rothenhäusler, K. (2023). Swiss-AL. Korpus und Workbench für mehrsprachige digitale Diskurse. In M. Kupietz & T. Schmidt (Eds.), Neue Entwicklungen in der Korpuslandschaft der Germanistik. Beiträge zur IDS-Methodenmesse 2022. Narr. S. 127–142. https://doi.org/10.24053/9783823396024
Dreesen, P., Krasselt, J., Runte, M., & Stücheli-Herlach, P. (2023). Operationalisierung der diskurslinguistischen Kategorie ,Akteur‘. In M. Meiler & M. Siefkes (Hrsg.), Linguistische Methodenreflexion im Aufbruch. De Gruyter. S. 263–294. https://doi.org/10.1515/9783111043616-010
Dreesen, P., & Krasselt, J. (2023). Respondenz von Philipp Dreesen & Julia Krasselt. In M. Meiler & M. Siefkes (Hrsg.), Linguistische Methodenreflexion im Aufbruch. De Gruyter S. 310–312. https://doi.org/10.1515/9783111043616-014
Krasselt, J. (2023). Korpus. In S. Schierholz (Hrsg.), Wörterbücher zur Sprach- und Kommunikationswissenschaft (WSK) .De Gruyter. https://www.degruyter.com/database/WSK/entry/wsk_id612d942e-8257-4e63-a362-191f4dd86e94/html
Juvalta, S., Speranza, C., Robin, D., El Maohub, Y., Krasselt, J., Dreesen, P., Dratva, J., & Suggs, L. S. (2023). Young people’s media use and adherence to preventive measures in the “infodemic”: Is it masked by political ideology? Social Science & Medicine, 317, 115596. https://doi.org/10.1016/j.socscimed.2022.115596
Krasselt, J. (2023). Review of Lavid-López, Maíz-Arévalo & Zamorano-Mansilla (2021): Corpora in Translation and Contrastive Research in the Digital Age: Recent Advances and Explorations. Target. International Journal of Translation Studies, 35(2), S.312-317. https://doi.org/10.1075/target.22166.kra
2022
Stücheli-Herlach, P., Dreesen, P., & Krasselt, J. (2022). Öffentliche Diskurse modellieren und simulieren. Wege der transdisziplinären Diskurslinguistik. Zeitschrift für Diskursforschung / Journal of Discourse Studies, 2, S.245–356. https://doi.org/10.3262/ZFD2202245
Dreesen, P., & Krasselt, J. (2022). Medienporträt: PI-News.net. In U. Backes, A. Gallus, E. Jesse, & T. Thieme (Hrsg.), Jahrbuch Extremismus & Demokratie (E & D), Bd. 34. Nomos. S.237–254. https://doi.org/10.5771/9783748936930-237
Krasselt, J., Robin, D., Fadda, M., Geutjes, A., Bubenhofer, N., Suzanne Suggs, L., & Dratva, J. (2022). Tick-Talk: Parental online discourse about TBE vaccination. Vaccine, 40(52), S.7538–7546. https://doi.org/10.1016/j.vaccine.2022.10.055
Krasselt, J., & Dreesen, P. (2022). „[D]er Koran muss wörtlich genommen werden (sagt der Koran)“. Korpuslinguistische Befunde zur Islamfeindlichkeit im Korandiskurs und ethische Überlegungen zu Bedingungen von Streitkultur. In C. Gürtler, M. Prinzing, & T. Zeilinger (Hrsg.), Streitkulturen. Medienethische Perspektiven auf gesellschaftliche Diskurse(Bd. 18). Nomos. S.95-112. https://doi.org/10.5771/9783748911098-95
Dreesen, Ph. & Krasselt, J. (2022): Social Bots als Stimmen im Diskurs. In Gredel, E. (Hrsg.), Diskurse – digital: Theorien, Methoden, Fallstudien. De Gruyter. S.271-281 https://doi.org/10.1515/9783110721447-014
Krasselt, J. (2022). Korpusanalyse. In S. Schierholz (Hrsg.), Wörterbücher zur Sprach- und Kommunikationswissenschaft (WSK). De Gruyter. [Eintrag]
Krasselt, J. (2022). Kookkurrenz. In S. Schierholz (Hrsg.), Wörterbücher zur Sprach- und Kommunikationswissenschaft (WSK). De Gruyter. [Eintrag]
Krasselt, J. (2022). korpusbasierte Diskursanalyse. In S. Schierholz (Hrsg.), Wörterbücher zur Sprach- und Kommunikationswissenschaft (WSK). De Gruyter. [Eintrag]
2021
Rocco, G., Dreesen, Ph. & Krasselt, J. (2021): Exploration zu deutschen und italienischen Akteursrollen in COVID-19-Diskursen. Methodologische Überlegungen und praktische Schlussfolgerungen zur Vergleichenden Diskurslinguistik. tekst i dyskurs – text und diskurs 15, S. 287-314. https://doi.org/10.7311/tid.15.2021.11
Dreesen, Ph. & Krasselt, J. (2021): Exploring and analyzing linguistic environment. In: François Cooren & Peter Stücheli-Herlach (Hrsg.), Handbook of Management Communication. De Gruyter. S. 389–408. https://doi.org/10.1515/9781501508059-021
Krasselt, J., Fluor, M., Rothenhäusler, K. & Dreesen, Ph. (2021): A Workbench for Corpus Linguistic Discourse Analysis. In: Dagmar Gromann et al. (Hrsg), Proceedings of the 3rd Conference of Language, Data and Knowledge. 35:1-35:10. https://doi.org/10.4230/OASIcs.LDK.2021.26
Dreesen, Ph., Krasselt, J. & Stücheli-Herlach, P. (2021): Diskursgemeinschaften in der digitalen Transformation. Begriffsbestimmungen, Zugänge und Ziele. In: Lublin Studies in Modern Languages and Literature 45(2). S.13-25. https://doi.org/10.17951/lsmll.2021.45.2.13-25
Runte, M. & Krasselt, J. (2021): Das Lexem Muße in den Referenzkorpora des Deutschen. Semantik mit Methoden der digitalen Linguistik erfassen. In: Monika Fludernik & Thomas Jürgasch (Hrsg.): Semantiken der Muße aus interdisziplinärer Perspektive. Mohr Siebeck. S.109-126. https://doi.org/10.1628/978-3-16-160815-5
Krasselt, J. (2021): Wortwolke. In: Wörterbücher zur Sprach- und Kommunikationswissenschaft (WSK) Online. De Gruyter. [Eintrag]
Krasselt, J. (2021): Korpusgetriebene Diskursanalyse. In: Wörterbücher zur Sprach- und Kommunikationswissenschaft (WSK) Online. De Gruyter. [Eintrag]
2020
Krasselt, J., Dreesen, Ph., Fluor, M., Mahlow, C., Rothenhäusler, K & Runte, M. (2020): Swiss-AL: A Multilingual Swiss Corpus for Applied Linguistics. In: Proceedings of the 12th International Conference on Language Resources and Evaluation, 4138-4144. Marseille, Frankreich. https://aclanthology.org/2020.lrec-1.510/
Runte, M. und Krasselt, J. (2020). Schlagwörter im Schweizer Energiediskurs. Korpuslinguistische Methoden zur Identifikation salienter Lexik im Diskurs. In Derya Gür-Seker (Hrsg.), Wörter, Wörterbücher, Wortschätze. (Korpus-) Linguistische Perspektiven vom Wort zur Wortschatzdidaktik. UVRR. S.1-20. [PDF]
2017
Krasselt, J. (2017). Der Verbalkomplex im Frühneuhochdeutschen. Eine korpuslinguistische Untersuchung zur Serialisierung zwei- und dreigliedriger Verbalkomplexe. Bochumer Linguistische Arbeitsberichte, 21. [PDF]
2015
Krasselt, J., Bollmann, M., Dipper, S., Petran, F. (2015). Guidelines für die Normalisierung historischer deutscher Texte. Guidelines for Normalizing Historical German Texts. Bochumer Linguistische Arbeitsberichte, 15. [PDF]
Dipper, S., Krasselt, J., Schultz-Balluff, S. (2015). Creating synopses of ‚parallel‘ historical manuscripts. Alignment guidelines, evaluation, and applications In: Gippert, J. und Gehrke, R. (Hrsg.), Challenges and Perspectives. Corpus Linguistics and Interdisciplinary Perspectives on Language (CLIP), vol. 5. Tübingen: Narr. [preprint]
2014
Bollmann, M., Petran, F., Dipper, S., Krasselt, J. (2014). CorA: A web-based annotation tool for historical and other non-standard language data. In: Proceedings of the 8th Workshop on Language Technology for Cultural Heritage, Social Sciences, and Humanities (LaTeCH), S. 86–90. Göteborg, Schweden. 2013 [PDF]
2013
Krasselt, J. (2013). Zur Serialisierung subordinierter Sätze im Verbalkomplex. Gegenwartssprachliche und Frühneuhochdeutsche Variation. In: Vogel, P. (Hg.), Sprachwandel und seine Reflexe im Neuhochdeutschen, S.127–142. Berlin, Boston: De Gruyter. [Verlagsseite]
Krasselt, J. (2013). Die Schreibsprachentwicklung in den Dresdner Stadtbüchern des 15. Jahrhunderts. In: Kolbeck, Ch., Krapp, R. and Rössler, P. (Hrsg.), Stadtsprache(n) – Variation und Wandel. Beiträge der 30. Tagung des Internationalen Arbeitskreises Historische Stadtsprachenforschung. Regensurg, 03.-05. Oktober 2012, S. 81–94. Heidelberg: Winter.
2012
Bollmann, M., Dipper, S., Krasselt, J., und Petran, F. (2012). Manual and semi-automatic normalization of historical spelling – Case studies from Early New High German. In: Proceedings of the First International Workshop on Language Technology for Historical Text(s) (LThist2012). Wien, Österreich. [PDF]
Bollmann, M., Dipper, S., Krasselt, J., and Petran, F. (2012). The Anselm Project: Tools for Automatic Analysis of a Parallel Corpus in Early New High German. 34. Jahrestagung der Deutschen Gesellschaft für Sprachwissenschaft (DGfS). Frankfurt, Deutschland.
Vorträge
2026
Krasselt, J., Lemmeneier-Batinić, D., Dreesen, P. Do we still need corpora and corpus analysis platforms? Discourse analysis in times of LLMs. LLMs4SSH. Shaping multilingual, multimodal AI for the social sciences and humanities. Workshop at LREC 2026, Palma, Spanien. 11.05.2026. Zenodo. https://doi.org/10.5281/zenodo.20051241
Krasselt, J., Dreesen, P., Lemmeneier-Batinić, D., Geckeler, S., Rothenhäusler, K., Fluor, M. Swiss-AL. Language Data Platform for Applied Sciences. Challenges in the Management of Large Corpora. Workshop at LREC 2026, Palma, Spanien. 11.05.2026. Zenodo. https://doi.org/10.5281/zenodo.20051025
Dreesen, P., & Krasselt, J. Das Deutsche in mehrsprachigen europäischen Öffentlichkeiten. Programmatik der Vergleichenden Diskurslinguistik und Anforderungen an offene digitale Forschungsinfrastrukturen. Jahrestagung des Leibniz-Instituts für Deutsche Sprache: Deutsch im europäischen Sprachraum. Stand und Perspektiven, Mannheim, 10.-12.03.2026. Zenodo. https://doi.org/10.5281/zenodo.20039078
Dreesen, P., D’Agostino, D., Krasselt, J., Stücheli-Herlach, P., & Suremann, I., Vaccination matters: Gesundheitskommunikation zwischen Aufklärung und Anklage, in der Event-Reihe Language matters, ZHAW, Winterthur. [Präsentation]
2025
Cristina Grisot, Alexandru Craevschi, Christian Futter, Teodora Vukovic, Jeremy Zehr, Julia Krasselt and Philipp Dreesen. The Swiss FAIR-compliant ecosystem of infrastructures 2.0. Clarin Annual Conference. Wien, Österreich, 30.September–02.Oktober 2025
Krasselt, J. Understanding the influence of AI-generated texts on public discourse: Towards a mulit-level corpus based analysis. Corpus linguistics 2040: Which data, which methods, which models? Institut für Deutsche Sprache, Mannheim, Deutschland. Zenodo. https://doi.org/10.5281/zenodo.20039577
Krasselt, J. An Applied Perspective on Corpus Linguistics and Infrastructure Development. Digital Infrastructure for Language Data in Switzerland. Lugano, 23. Juni 2025.
Krasselt, J., & Zehr, J. One Query to search them all: Developing a Federated Content Search for linguistic corpora in Switzerland. Digital Infrastructure for Language Data in Switzerland. Lugano, 23. Juni 2025.
Krasselt, J., & Suremann, I. Corpus-Based Comparative Discourse Analysis: Methodological Challenges and Technical Affordances. Corpus Linguistics 2025, Birmingham, UK.
Dreesen, P., & Krasselt, J. Gesellschaftliche Vorstellungen von Dialog aus metapragmatischer Perspektive. 28. Deutscher Germanistentag, Braunschweig, Deutschland, 14.-17. September 2025.
Dreesen, P.; Suremann, I.; Geckeler, S.; Lemmenmeier, D.; Krasselt, J.; Rothenhäusler, K.; Fluor, M., Herausfinden, worum es wirklich geht : kreative Kombination von KI-unterstützter Diskurs- und Korpuslinguistik. VALS-ASLA Studientag, Winterthur, Schweiz, 6. Juni 2025. [Präsentation]
Gerber, A., & Krasselt, J. Von der Utopie zur Norm: Öko-Architektur als kulturelles, sprachliches und gesellschaftliches Phänomen. Ringvorlesung „Forschungsräume: Aktuelle Ansätze von Architekturgeschiche bis Denkmalpflege. 28.10.2025. Universität Bern.
2024
Dreesen, P.; Krasselt, J.; Stücheli-Herlach, P.; Suremann, I. Die Analyse des öffentlichen Impfdiskurses. In: 360° Winterthur Symposium, Winterthur, Switzerland, 28-29 November 2024.
Swiss-AL: Eine Plattform für Sprachdaten in den Angewandten Wissenschaften. Workshop und Messestand auf dem Hands-on-Forum des GAL-Forschungsfokus Digitale Infrastrukturen für die Angewandte Linguistik (DIAL), GAL Jahrestagung 2024 an der TU Dresden, 11.-13. September 2024. [Poster]
Juvalta, S., & Krasselt, J. Kindergesundheit in Schweizer Online-Nachrichten. Cypher-Symposium, Winterthur, 6.11.2024.
2023
Dreesen, P.; Krasselt, J.; Dratva, J.; Stücheli-Herlach, P.; Suggs, S.; Juvalta, S.; Speranza, C.; Robin, D.; Baumann, D.; El Maohub, Y.; Rothenhäusler, K.; Fluor, M.; Rocco, G.; Canavese, P.. COVIDisc : COVID-19 pandemic discourses in Switzerland – a focus on 15-34 year olds. SNSF Corona Research Conference, Thun, Switzerland, 21-23 March 2023. [Poster] [Präsentation]
Dreesen, P.; Krasselt, J. „Flüchtlinge als Waffe“ : Entstehung und Bewertung einer herausfordernden Formel. In: VALS-ASLA Studientag: Angewandte Linguistik in Krisenzeiten, Zürich, Schweiz, 27. Januar 2023. [Präsentation]
Krasselt, J. „The Word of the Year Initiative in Switzerland: Data, Methods and Tools“. AILA World Congress, 18. Juli 2023. Lyon/hybrid.
2022
Dreesen, P., & Krasselt, J. (29.09.2022). Medienideologische Diskurspositionen. Befunde zum ARD-Bürgerdialog. Gesellschaft für Angewandte Linguistik (GAL), Sektionentagung, Würzburg, Deutschland.
Schwägerl, C., Stücheli-Herlach, P., Dreesen, P., & Krasselt, J. (September 2022). Engaging in Conversation and Discourse. Identification of Risk Indicators in the Stakeholder Dialogue of a German Public Service Media Organization. EUPRERA. 23rd Annual Congress. Wien, Österreich.
Dreesen, P., & Krasselt, J. (17.02.2022). Korpuszentrierte Diskursanalyse: Diskursmodellierung und quantitative Analyseansätze. Methodologien der Quantitativen Sozialforschung, Berlin, Deutschland. [Präsentation]
Dreesen, P., & Krasselt, J. (18.02.2022). Results of the COVIDisc project on the production, perception, and reception of COVID-19 discourses. Forschungsforum der Angewandten Linguistik in der Schweiz 2022, online.
Krasselt., J., & Dreesen, P. (02.12.2022). Forschungsergebnisse zu automatisiertem Fahren als diskursivem Gegenstand. Vortrag beim Artificial Friday – Linguistische Perspektiven auf künstliche Intelligenz, online.
Krasselt, J., Dreesen, P., Fluor, M., Rothenhäusler, K., Runte, M., Mahlow, C., Ulasik, A. Swiss-AL: Korpus und Workbench für mehrsprachige digitale Diskurse. Korpora in der Germanstischen Sprachwissenschaft – mündlich, schriftlich, multimedial. Methodenmesse, Jahrestagung des Leibniz-Instituts für Deutsche Sprache, 15.-17. März 2022, Online.
Krasselt, J. Tracking Discourses on Antibiotic Resistance with Corpus Linguistic Methods. Applied NLP Technologies for Physical and Mental Health in Practice. Applied Machine Learning Days. Lausanne, 28.03.2022.
2021
Krasselt, J., & Dreesen, P. (2021, September 15). Zur Genese von Diskurspositionen auf Twitter. Eine quantitative Analyse von Twitter-Profilen im Schweizer COVID-19-Diskurs. Gesellschaft für Angewandte Linguistik (GAL), Sektionentagung, Würzburg, Deutschland (online).
Krasselt, J., Fluor, M., Rothenhäusler, K., & Dreesen, P. (2021, September 3). A Workbench for Corpus Linguistic Discourse Analysis. LANGUAGE, DATA and KNOWLEDGE, Zaragoza, Spain.
Krasselt, J. & Dreesen, P. (2021, July 14). Patterns of Language Use Reveal Digital Actor Groups. On Combining Topic Modeling and Social Network Analysis. Corpus Linguistics 2021, Limerick, Ireland (online)
Krasselt, J., & Dreesen, P. (2021, August 2). Inclusion of majority: Discoursive dynamics of responsibility during the COVID-19 pandemic. 17th International Pragmatics Conference (IPrA), Winterthur, Switzerland (online). [Präsentation]
Dreesen, P., Krasselt, J., & Rothenhäusler, K. (2021, März 18). Hapaxe, Morpheme und Produktivität im COVID-19-Diskurs. Tagung Diskursmorphologie, online. [Präsentation]
Krasselt, J., & Dreesen, P. (2021, Februar 18). Ausschliessungspraktiken und Rationalitätsforderungen in Diskursen über den Islam: Datenzentrierte diskursanalytische Befunde in medienethischer Diskussion. Jahrestagung der DGPuK-Fachgruppe „Kommunikations- und Medienethik“, Erlangen, Deutschland (online). [Präsentation]
Dreesen, P., Krasselt, J., Dratva, J., Stücheli-Herlach, P., Suggs, S. (17. November 2021). COVIDisc – A Focus on Vector Populations. Poster auf der «Scientific Reality Check», Nationales Forschungsprogramm „Covid-19“ (NFP 78).
Dreesen, P., & Krasselt, J. (26. März 2021). Representation and its dependencies. Discourse patterns and conditions of speaking for/about young criminals. Vortrag auf der Online Tagung Participation through Language: Actors, Practices, Ideologies. [Präsentation]
Krasselt, J. Lockdown, Shutdown, Stillstand. Sprachgebrauchsmuster in Corona-Diskursen und wie man sie korpuslinguistisch erfassen kann. Linguistisches Kolloquium, Julius-Maximilians-Universität Würzburg, 12. Januar 2021.
2020
Dreesen, P., & Krasselt, J. (2020, November 23). Evaluations of the Quran in right-wing populist media: Metapragmatic sequence analyses with topic modeling. Digital Practices. Reading, Writing and Evaluation on the Web, Basel, Switzerland (online). [Präsentation]
Krasselt, J. (2020, Januar 17). Sprechen über Krankheiten: Gesundheitskommunikation im Web 2.0 [Invited talk]. Public Health 2020 : Dreiländertagung: Gesundheitskommunikation im 21. Jahrhundert, Steckborn, Schweiz.
2019
Krasselt, J., Klopfenstein-Frei, N., Mirco, S., Bubenhofer, Noah, Calleri, S., Rosenberger-Staub, N., & Wyss, V. (2019, November 6). Capturing media resonance through corpus-based discourse analysis: Method development using the example of energy and social assistance discourse. DigiKomm-Fachgruppentagung «Automating Communication», Berlin, Deutschland.
Krasselt, J. (2019, Oktober 3). «Unser Baby hat Fieber!»: Methoden der Digitalen Linguistik zur Analyse von Gesundheitsthemen in Elternforen. 1. Digital Health Lab Day (ZHAW), Wädenswil, Schweiz.
Stücheli-Herlach, P., Krasselt, J., Dreesen, P., & Calleri, S. (2019, Juni 26). #Wortwahl – die Politik der Schlagworte: Empirische Ergebnisse aus dem Projekt «Energiediskurse in der Schweiz». IAM live 2019, Winterthur, Schweiz.
2018
Ehrensberger-Dow, M., Stücheli-Herlach, P., Krasselt, J., Dreesen, P., & Batz, D. (2018, April 12). Exploring Swiss multilingual discourses: Methodological considerations and preliminary findings in the case of national energy policy. Annual Conference of the Swiss Association of Communication and Media Research (SACM-SGKM), Lugano, Switzerland.
Visualisierungen
Ich habe ein grosses Interesse für die Visualisierung korpuslinguistischer Analysen. Die folgenden Visualisierungen habe ich im Zusammenhang von Forschungsprojekten erstellt, beispielsweise in diskurslinguistischen Forschungsprojekten für Schweizer Bundesbehörden, kantonale Behörden und Kultureinrichtungen. Alle Darstellungen basieren auf Daten des Schweizer Korpus Swiss-AL und sind mit R erstellt.
Topic Modeling (I)
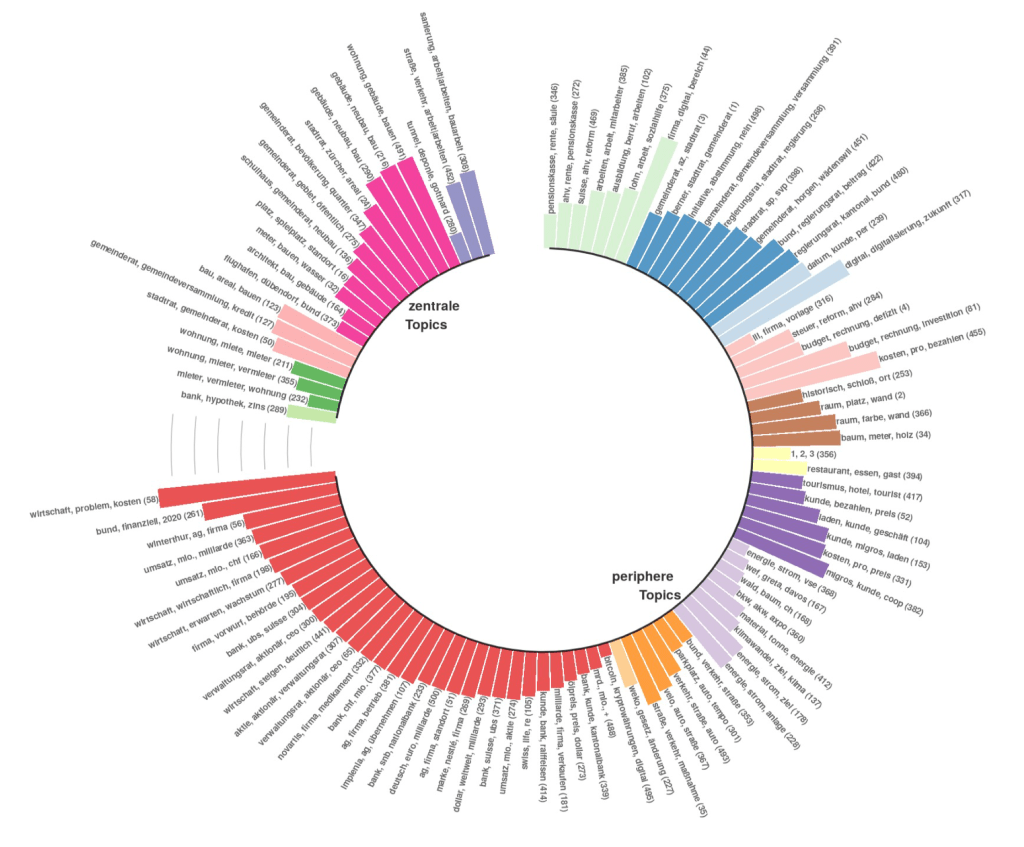
Thematische Cluster
Topic Modeling kann zur Identifikation von thematischen Clustern in Diskursen genutzt werden. In der Abbildung repräsentiert jeder Balken ein mit LDA berechnetes Topic, thematische Cluster sind farblich codiert. Die Höhe der Balken repräsentiert die Anzahl an Texten, in denen ein Topic vorkommt. Jeder Balken ist mit den Top 3 Wörtern eines Topics gelabelt. Ausserdem wird in der Abbildung zwischen für den untersuchten Diskurs zentralen und peripheren thematischen Clustern unterschieden.
verwendete R-Pakete: mallet, ggplot2, polmineR, dplyr
Topic Modeling (II)
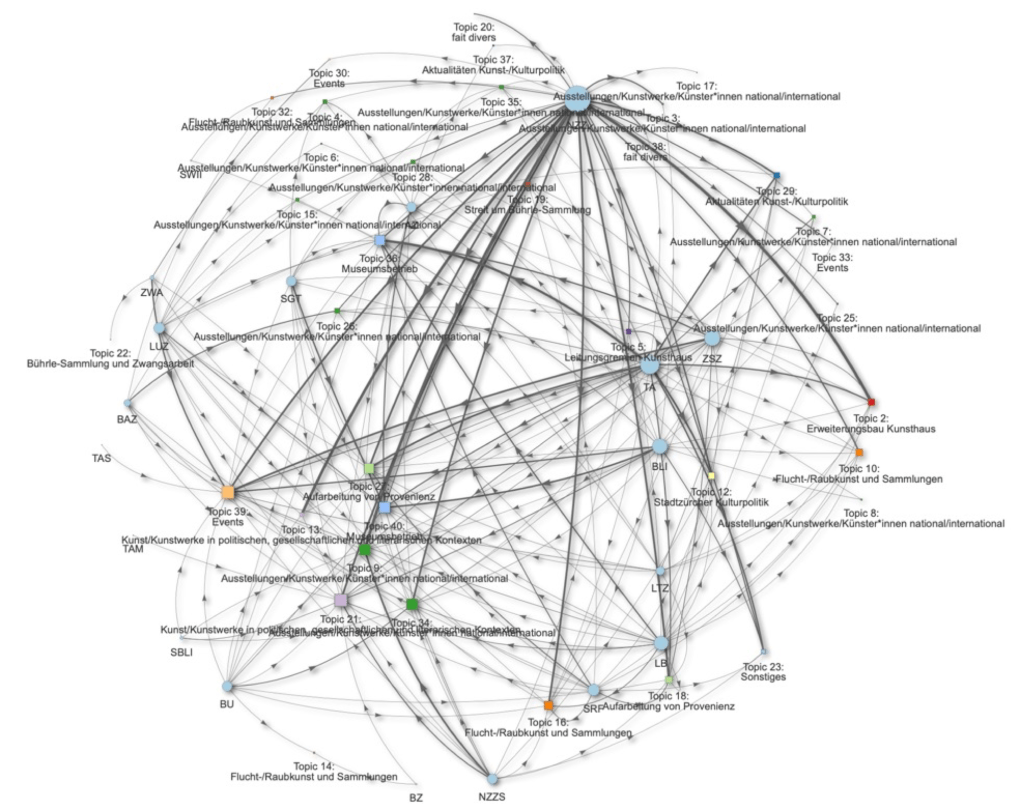
Netzwerke
Topic Modeling kann genutzt werden, um thematische Menüs von Akteuren visuell in Diskursnetzwerken darstellbar zu machen. Die Abbildung zeigt ein Netzwerk aus Akteuren (runde Knoten) und Topics (quadratische Knoten), die durch Kanten verbunden sind. Je dicker eine Kante, umso häufiger wird ein Topic von einem Akteur verwendet.
verwendete R-Pakete: mallet, ggplot2, polmineR, visNetwork, dplyr
Topic Modeling (III)
Diskursgenealogie
Topic Modeling kann genutzt werden, um Topics im Zeitverlauf zu analysieren, um beispielsweise herauszufinden, zu welchen Zeitpunkten auffällig viele Texte mit einem Topic im Korpus vorhanden sind. Mit Hilfe von Close-Reading-Verfahren können Ereignisse identifiziert werden, die zu solchen Peaks führen. Die Abbildung zeigt zwei Topics aus einem Korpus zu Antibiotikadiskursen (blau und rot) im Zeitverlauf, auffällige Peaks sind mit Ereignissen gelabelt.
verwendete R-Pakete: mallet, ggplot, ggrepel, polmineR

Netzwerkanalysen
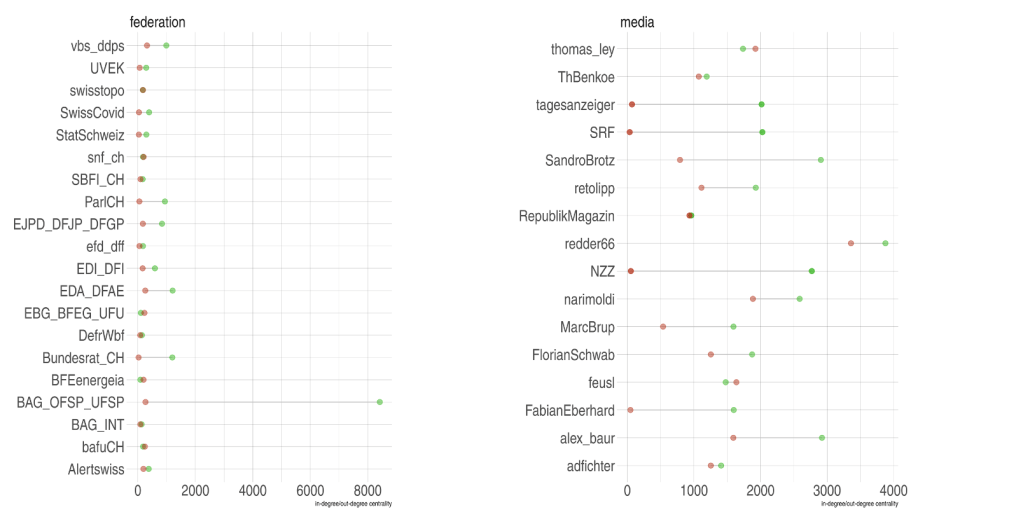
Interaktionen auf Twitter
Die Abbildung zeigt das Interaktionsprofil für ausgewählte Twitteraccounts, basierend auf einer zugrundeliegenden Netzwerkdarstellung. Es wird zwischen eingehenden (ein Account wird retweetet/zitiert/wird erwähnt = grüne Punkte) und ausgehenden Kanten (ein Account retweetet/zitiert/erwähnt = rote Punkte) unterschieden.
verwendete R-Pakete: ggplot2
Vokabular
Kookurrenzen (I)
Die Abbildung zeigt das textbasierte Ko-Vorkommen von ausgewählten Wörtern mit den Schlüsselwörtern „Antibiotika“ (AB) und „Antibiotikaresistenz“ (AR). Je grösser und heller ein Quadrat, umso häufiger ist das Ko-Vorkommen im Korpus belegt. Zusätzlich wird unterschieden zwischen unterschiedlichen Gruppen von Texten (hier: Texte von Akteuren aus der Wissenschaft, Wirtschaft, Politik und den Medien).
verwendete R-Pakete: ggplot2, polmineR

Vokabular
Kookkurrenzen (II)
Die Abbildung zeigt eine weitere Möglichkeit, das gemeinsame Vorkommen von Wörter im Text darzustellen, diesmal im Zeitverlauf. Die Höhe der Balken zeigt die Anzahl an Texten, in denen das 2-gram „erneuerbare Energie“ vorkommt. Je dunkler ein Balken eingefärbt ist, umso häufiger kommt in den Texten auch das Toponym „Fukushima“ vor. Die X-Achse repräsentiert Quartale zwischen 2005 und 2017.
verwendete R-Pakete: polmineR, ggplot2
